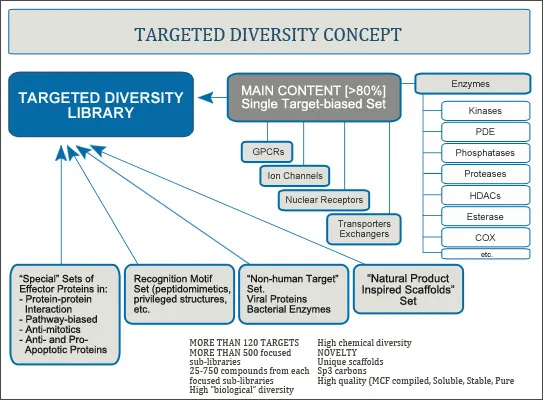
Targeted Diversity Library

{kind=link}
{kind=link}
{kind=link}
ChemDiv introduces the concept of Targeted Diversity which is intended for the design of high quality libraries of drug-like compounds that have been focused against various biological targets.
Targeted diversity signifies the superposition of highly diverse chemical space on the assortment of divergent families or sub-families of targets and unique biomolecules.