Bibliothèque ciblée
Méthodes informatiques de création de bibliothèque ciblée.
Cerveau de silicium
Aujourd'hui, la conception de médicaments in silico (CADD) est utilisée par la grande majorité des leaders pharmaceutiques, y compris ChemDiv. Nous donnerons ici trois exemples d'utilisation de CADD pour la création de bibliothèques ciblées.
Réseaux de neurones récurrents (RNN)
L'une des méthodes CADD en développement rapide implique les RNN, où, après la formation, le réseau génère une sortie similaire à l'entrée, c'est-à-dire de nouvelles structures moléculaires imitant celles de l'ensemble de données d'apprentissage.
Dans l'article [1], la création automatisée de bibliothèques ciblées via l'apprentissage par transfert - c'est-à-dire l'entraînement sur un large ensemble (de molécules, dans ce cas, mais le concept ne s'y limite pas) d'abord, puis le réglage avec des échantillons plus petits pour l'optimisation des prospects a été explorée.
Après avoir utilisé un ensemble de données ChEMBL pour former un RNN, des ensembles de transfert qui imitent ceux qui se produisent habituellement dans le flux de travail de la chimie médicinale ont été sélectionnés.
Parmi toutes les mesures choisies, deux étaient essentielles pour évaluer les performances du réseau : un score de nouveauté unique et un score de proximité chimique.
De manière quelque peu contre-intuitive, les ensembles de données plus petits nécessitaient plus de formation et les plus grands convenaient avec moins de cycles. Un nombre de fragments plus faible (ce qui signifie qu'il y avait moins de groupes distincts - fragments - dans l'ensemble de données) a réduit l'unicité, car les données d'entraînement étaient plus homogènes.
Ces résultats sont présentés dans ce tableau (les numéros d'en-tête se réfèrent aux époques terminées (c'est-à-dire aux cycles), les cellules indiquant dans quelle mesure la sortie, en pourcentage, avait un score de nouveauté unique faible (moins d'un quart) :
| Nom de fichier | Nombre de fragments | 5 | dix | 12 | 15 | 17 | 20 |
| DHODH complet | 66 | -- | 1 | 59 | 91 | 96 | 100 |
| METAP2 complet | 59 | -- | 60 | 78 | 88 | 91 | 100 |
| MMP-12 complet | 31 | 33 | 66 | 80 | 94 | 99 | 100 |
| P2X7 complet | 131 | -- | -- | -- | 18 | 78 | 99 |
| SLC22A12 complet | 49 | -- | 75 | 98 | 100 | 100 | |
| Sous-ensemble DHODH | 41 | -- | 46 | 62 | 88 | 98 | 100 |
| Sous-ensemble METAP2 | 40 | -- | 60 | 76 | 92 | 100 | 100 |
| Sous-ensemble MMP-12 | 22 | 50 | 80 | 87 | 97 | 100 | 100 |
| Sous-ensemble P2X7 | 64 | -- | 34 | 85 | 95 | 99 | 100 |
| Sous-ensemble SLC22A12 | 32 | 13 | 75 | 88 | 100 | 100 | 100 |
| US-20090018134 | 33 | 8 | 58 | 79 | 91 | 93 | 99 |
| US-20090286778 | 123 | -- | 21 | 55 | 75 | 81 | 83 |
| US-20100016279 | 73 | -- | 82 | 97 | 99 | 100 | 100 |
| US-20120157425 | 91 | 1 | 85 | 92 | 99 | 100 | 100 |
| WO-2010079443 | 54 | -- | -- | -- | 8 | 60 | 92 |
| WO-2011075515 | 137 | -- | 2 | 42 | 89 | 93 | 100 |
| WO-2012053186 | 44 | 1 | 66 | 87 | 94 | 100 | 100 |
| WO-2012067965 | 110 | -- | 34 | 85 | 97 | 98 | 100 |
SIFt
Une autre technique courante dans CADD est le SBF (focalisation basée sur la structure), dans laquelle des contraintes d'interaction spécifiques sont utilisées comme base pour concevoir de nouveaux composés chimiques qui pourraient se lier à la cible.
Dans l'article [2], les chercheurs ont développé une méthode d'analyse et de visualisation de données à grande échelle - l'empreinte digitale d'informations structurelles (SIFt). Afin de tirer parti plus efficacement de la nature tridimensionnelle des molécules, le r-SIFt a été développé, le « r » faisant référence à différents groupes R.
Après avoir assemblé des bibliothèques virtuelles et des poses d'amarrage, des descripteurs bidimensionnels ont été trouvés via Pipeline Pilot, à quel point des r-SIFts ont été générés, intégrant les paramètres de liaison dans l'empreinte digitale. Pour les 10 poses avec les Cscores les plus élevés (pour les inhibiteurs de la MAP kinase p38), des r-SIFts ont ensuite été générés, la meilleure pose étant sélectionnée en calculant le coefficient de Tanimoto.
Les résultats ont été évalués en mesurant les précisions prédictives des arbres de décision réalisés à l'aide des r-SIFT produits précédemment.
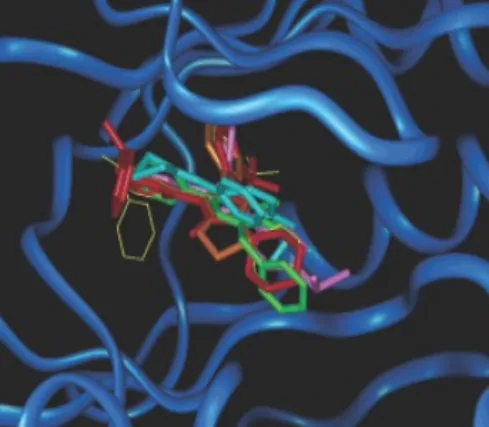
Combiné à une boîte à outils conventionnelle, r-SIFt s'est avéré être un excellent outil de visualisation qui zoomait sur des parties particulières de la molécule. La figure suivante montre les similitudes entre les inhibiteurs de p38 et, après un examen plus approfondi, révèle les différences.

b est une superposition de la meilleure pose d'amarrage (c-f sont des inhibiteurs de p38, g ne l'est pas). La structure cocristalline de c est représentée par une ligne jaune. Les inhibiteurs se lient de manière similaire : les parties violettes sont près de la charnière, les bleues sont concentrées dans la poche hydrophobe.

Structures et groupes R. 1-5 correspondent à c-g dans l'image précédente.
résultats. Un trifluorobenzène R1 de 1 par rapport à un plus petit 3-fluorophénol R1 explique le degré d'interaction plus élevé dans la région hydrophobe.
Algorithme génétique multiobjectif
Un algorithme génétique multiobjectif (MOGA) a été utilisé comme base pour MoSELECT - un programme qui recherche des solutions dans l'espace virtuel et présente les connexions entre différentes cibles [3].
Les tâches avec de nombreux objectifs ont souvent différentes gammes de solutions, chacune d'entre elles ayant des compromis différents. Un algorithme génétique standard recherche ces lignées séparément, contrairement à MOGA, qui le fait simultanément, en utilisant l'idée de « dominance » :

La tâche consiste à minimiser f1 et f2. Les cercles pleins sont pour les réponses non dominées, ce qui signifie qu'il n'y a pas de meilleures solutions pour les deux objectifs. Les points vides sont dominés, avec un nombre indiquant combien de "dominateurs" (meilleures solutions) sont présents.
Lorsqu'il a été chargé de créer une bibliothèque ciblée pour une molécule aléatoire à partir de la bibliothèque de 2-Aminothiazole, en optimisant la similarité (mesurée par les empreintes digitales de la lumière du jour et le coefficient de Tanimoto) et le coût, SELECT - qui a utilisé un algorithme génétique standard - a fourni seulement une solution unilatéralement adéquate – soit les moyennes 0,832 ; 48 289,4 USD ou 0 696 USD ; 1 675,2. La seule façon de parvenir à un compromis - choisir minutieusement les poids - est difficile pour des objectifs aussi démesurés. MoSELECT, au lieu de donner des solutions uniques, crée toute la famille de réponses non dominées et permet un choix plus facile pour décider du compromis :

La version étendue de la troisième figure, toute la famille de solutions est montrée.
Conclusion
ChemDiv offre des services CADD de première classe dans le domaine de la chimie informatique, qui incluent le criblage virtuel, l'amarrage, l'optimisation hit2lead et autres.
Littérature
[1] Lignes directrices pour la génération moléculaire basée sur l'apprentissage par transfert RNN de bibliothèques ciblées ; Amabilino et al., Journal of Chemical Information and Modeling 2020, 60, 12, 5699–5713
[2] Conception basée sur les connaissances de bibliothèques ciblées utilisant l'interaction protéine-ligand