焦点を絞ったライブラリ作成のコンピューターベースの方法
シリコン脳
今日、インシリコ ドラッグ デザイン (CADD) は、ChemDiv を含む製薬業界のリーダーの大多数によって使用されています。 ここでは、CADD を使用して特定のライブラリを作成する 3 つの例を示します。
リカーリング ニューラル ネットワーク (RNN)
急速に発展している CADD 手法の 1 つに RNN が含まれます。RNN では、トレーニング後にネットワークが入力と同様の出力、つまり、学習データセット内のものを模倣した新しい分子構造を生成します。
記事 [1] では、転移学習による焦点を絞ったライブラリ の自動作成について説明しました。つまり、最初に大規模なセット (この場合は分子のセットですが、概念は分子に限定されません) でトレーニングし、次にチューニングします。 リード最適化のためのより小さなサンプルを使用して検討されました。
ChEMBL データセットを使用して RNN をトレーニングした後、医薬品化学ワークフローで通常発生するものを模倣する転送セットが選択されました。
選択されたすべての指標のうち、ネットワークのパフォーマンスを評価するための鍵となったのは、ユニークノベルティ スコアと化学的近接性スコアの 2 つです。
少し直感に反して、小さなデータセットはより多くのトレーニングを必要とし、大きなデータセットはより少ないサイクルで問題ありませんでした。 トレーニング データがより均質であるため、フラグメント数が少ない (つまり、データセット内の異なるグループ (フラグメント) が少ないことを意味します) と、一意性が低くなります。
ファイル名
フラグ数
5
10
12
15
17
20
DHODフル
66
--
1
59
91
96
100
METAP2 フル
59
--
60
78
88
91
100
MMP-12 フル
31
33
66
80
94
99
100
P2X7 フル
131
--
--
--
18
78
99
SLC22A12 フル
49
--
75
83
98
100
100
DHODH サブセット
41
--
46
62
88
98
100
METAP2 サブセット
40
--
60
76
92
100
100
MMP-12 サブセット
22
50
80
87
97
100
100
P2X7 サブセット
64
--
34
85
95
99
100
SLC22A12 サブセット
32
13
75
88
100
100
100
US-20090018134
33
8
58
79
91
93
99
US-20090286778
123
--
21
55
75
81
83
US-20100016279
73
--
82
97
99
100
100
US-20120157425
91
1
85
92
99
100
100
WO-2010079443
54
--
--
--
8
60
92
WO-2011075515
137
--
2
42
89
93
100
WO-2012053186
44
1
66
87
94
100
100
WO-2012067965
110
--
34
85
97
98
100
SIFt
CADD のもう 1 つの一般的な手法は、SBF (構造ベース フォーカシング) です。この手法では、特定の相互作用制約を基礎として使用して、ターゲットに結合できる新しい化合物を設計します。
記事 [2] で、研究者は大規模なデータ分析と視覚化のための方法、つまり構造情報フィンガープリント (SIFt) を開発しました。 分子の三次元的性質をより効果的に活用するために、r-SIFt が開発されました。「r」は異なる R グループを指します。
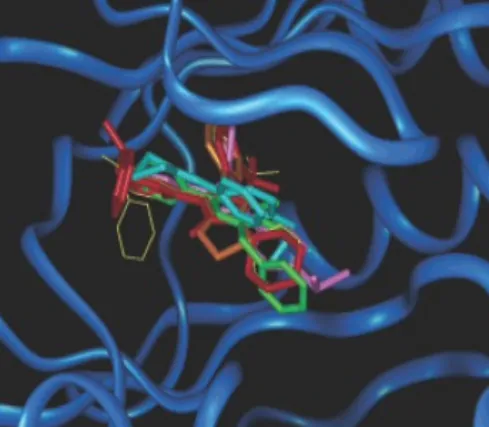
b は最適なドッキング ポーズのオーバーレイです (c ~ f は p38 阻害剤、g はそうではありません)。 c の共結晶構造は黄色の線で示されています。 阻害剤も同様の方法で結合します。紫色の部分はヒンジの近くにあり、青色の部分は疎水性ポケットに集中しています。
構造と R グループ。 1-5 は前の図の c-g に対応します。
つまり、1 の R2 (紫色の c) は、他のものよりもヒンジとの接触が多く、これは以前の
多目的遺伝的アルゴリズム
多目的遺伝的アルゴリズム (MOGA) は、仮想空間でソリューションを検索し、異なるターゲット間の接続を提示するプログラムである MoSELECT の基盤として採用されました [3]。
多くの目的を持つタスクには、さまざまな解決策があり、それぞれに異なるトレードオフがあることがよくあります。 標準的な遺伝的アルゴリズムは、これらの行を個別に検索しますが、MOGA は「優位性」の考え方を利用して同時に検索します。
タスクは、f1 と f2 を最小化することです。 塗りつぶされた円は、非支配的な回答に対するものです。つまり、両方の目標に対してより良い解決策はありません。 空のドットが支配的であり、数字は「支配者」 (より良い解決策) がいくつ存在するかを示しています。
2-アミノチアゾール ライブラリからランダムな分子の焦点を絞ったライブラリ を作成し、類似性 (デイライト フィンガープリントとタニモト係数によって測定) とコストを最適化する作業を行うと、標準的な遺伝的アルゴリズムを使用した SELECT が提供されました。 一方的に適切な解決策のみ – 平均 0,832; 48 米ドル 289,4 または 0,696。 1 675,2. 妥協点を達成する唯一の方法、つまり骨の折れる重みの選択は、このような釣り合いの取れていない目標には困難です。 MoSELECT は、単一のソリューションを提供するのではなく、非支配的な回答のファミリー全体を作成し、妥協点を決定する際のより簡単な選択を可能にします。
結論
全体として、インシリコ技術は製薬業界において非常に価値のあるツールです。
文学
[1] RNN 転移学習ベースのフォーカス ライブラリの分子生成のガイドライン。 Amabilino et al., Journal of Chemical Information and Modeling 2020, 60, 12, 5699–5713