PRMT5-targeted compound library

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
PRMT5-targeted compound library
1. Purpose and target context
The PRMT5 library is a focused set of 3,868 candidate small molecules for follow-up screening around known PRMT5 inhibitor chemotypes and PRMT5/MEP50-related mechanistic space. The set is intended to preserve scaffold-level proximity to the reference PRMT5 chemistry while allowing additional analogs through a relaxed 2D fingerprint threshold of 0.50.
PRMT5 is a protein arginine methyltransferase involved in gene regulation and other cellular processes. RCSB PDB entry 4GQB is the crystal structure of the human PRMT5:MEP50 complex; the structure page reports X-ray diffraction at 2.06 A resolution. The RCSB/PDB abstract describes PRMT5 as acting in a multimeric complex with MEP50/WDR77, which supports substrate and partner interactions. This target context motivates a library organized not only by structural similarity, but also by transferred mechanism of action annotations.
2. Input data
The PRMT5 reference set consisted of 1,351 molecules. This set was used as the structural and mechanistic anchor for library construction: each reference compound represented known PRMT5- or PRMT5/MEP50-related chemistry and carried reference information such as molecular descriptors, Bemis-Murcko scaffold, fingerprint representation and available mechanism-of-action annotations. The reference set defined the PRMT5 chemical space used for both similarity searching and scaffold matching.
For the screening stage, the candidate pool contained 569,633 records across seven MCF-passed SDF files. RDKit sanitization and largest-fragment standardization produced 569,632 valid records. Two exact canonical-SMILES matches to the PRMT5 reference set were skipped, because the final library was intended to add new candidate molecules rather than duplicate compounds already present in the reference set.
3. Selection workflow
- Each molecule was sanitized with RDKit. For salts or multi-fragment records, the largest organic fragment was retained.
- Canonical isomeric SMILES were calculated for duplicate detection and exact-reference exclusion.
- Morgan fingerprints were calculated with radius 2 and 2,048 bits.
- For each candidate, Tanimoto similarity was computed against every molecule in the PRMT5 reference set.
- A molecule passed the similarity route if its maximum Morgan/Tanimoto score was >= 0.50.
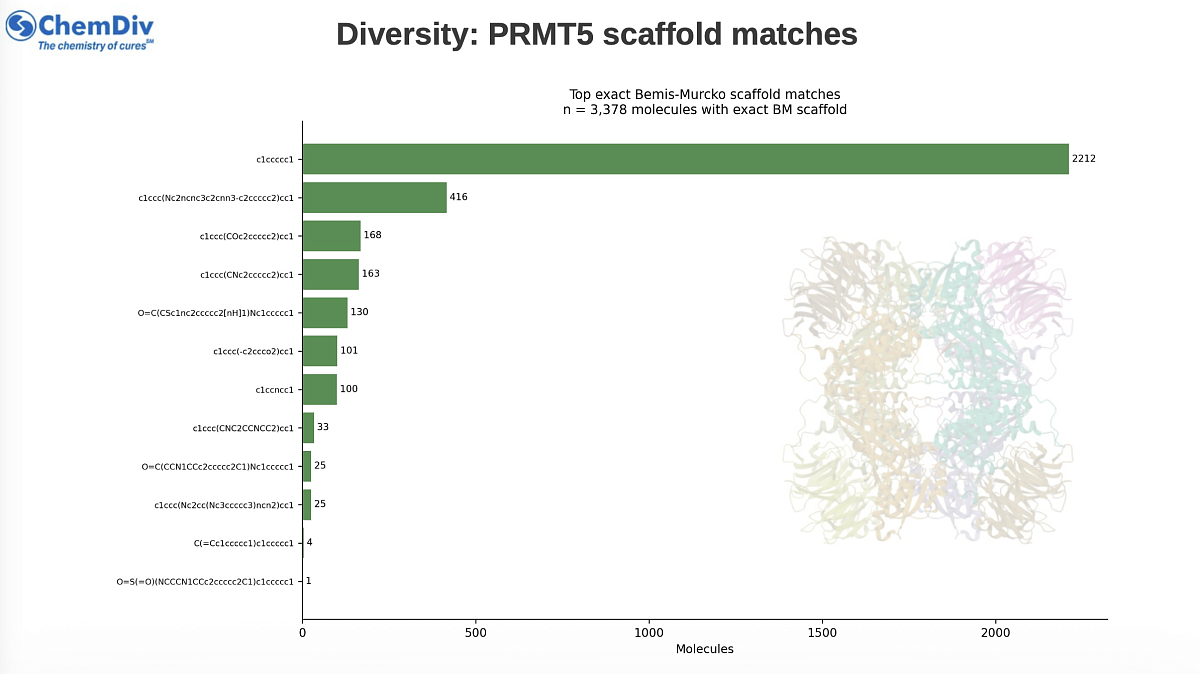
- A Bemis-Murcko scaffold was generated for each candidate and compared to the PRMT5 reference scaffolds.
- A molecule passed the scaffold route if the non-empty Bemis-Murcko scaffold matched a reference scaffold exactly.
- The final logical rule was OR: similarity >= 0.50 OR exact BM scaffold match.
- Selected molecules were globally deduplicated by canonical isomeric SMILES and ranked by similarity, scaffold flag and descriptor-profile fit.
4. Descriptor and MoA annotation
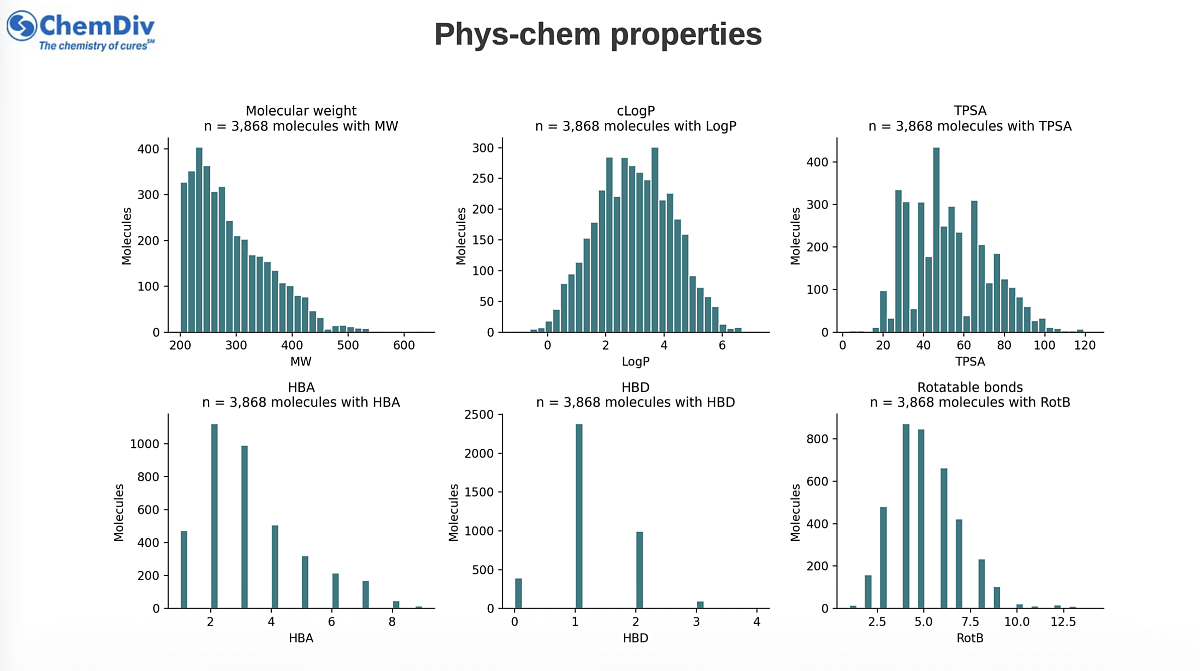
The SDF and CSV include Formula, MW, HBA, HBD, RotB, AromaticRings, TPSA, LogP, N/O atom count, number of chiral centers, descriptor-profile flags, selection flags, reference identifiers, matched scaffold information and MoA fields.
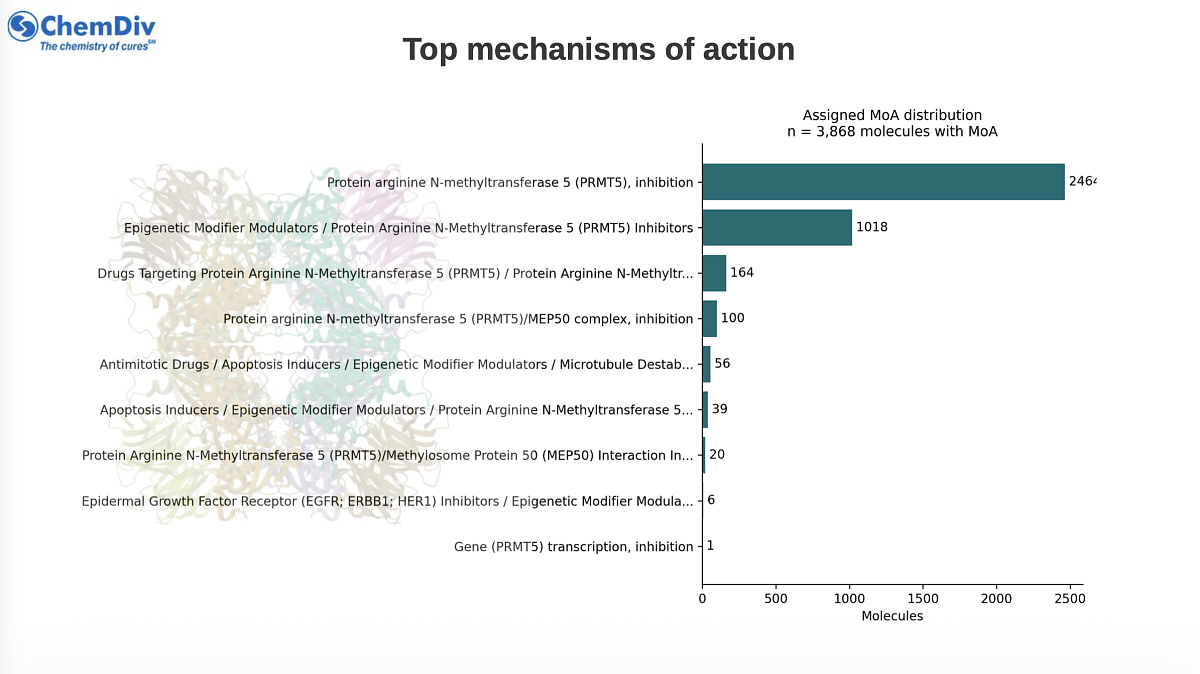
MoA assignment was reference-driven. If a candidate had an exact BM-scaffold match, MoA was copied from the closest reference molecule within that scaffold, using the same Morgan/Tanimoto scores. If no scaffold match was present, MoA was copied from the nearest fingerprint reference. The primary MoA field was filled by priority: Mechanism_of_Action, then Pharmacological Activity, then Experimental Activity. Supporting fields preserve the source reference ID, reference SMILES, reference BM scaffold and original MoA-related reference fields.
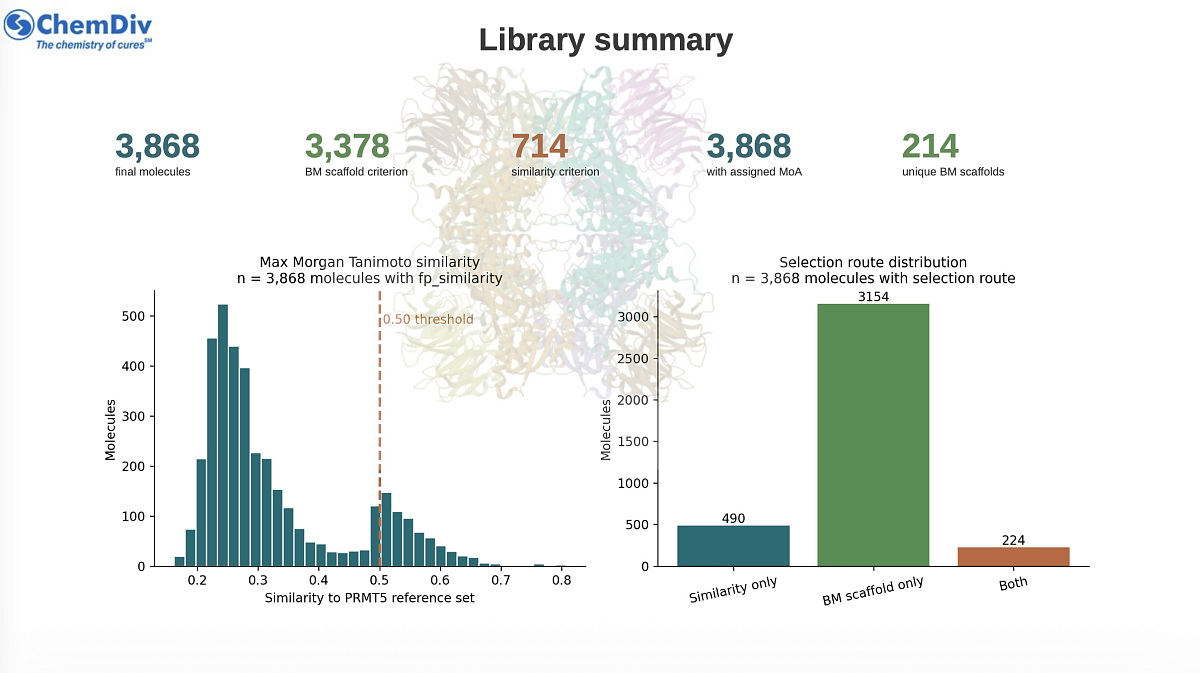
5. Final library summary
|
Metric |
Value |
|
Final molecules |
3,868 |
|
Selected before global deduplication |
3,868 |
|
Similarity criterion met |
714 |
|
Exact BM scaffold criterion met |
3,378 |
|
Both criteria met |
224 |
|
Similarity only |
490 |
|
BM scaffold only |
3,154 |
|
Unique selected BM scaffolds |
214 |
|
Molecules with assigned MoA |
3,868 |
|
Unique assigned MoA values |
9 |
|
FP similarity min / median / max |
0.161 / 0.278 / 0.807 |
|
MW min / median / max |
200.1 / 274.3 / 632.9 |
|
LogP min / median / max |
-1.13 / 2.99 / 7.19 |
|
TPSA min / median / max |
3.2 / 50.4 / 123.2 |
|
Descriptor fit fraction min / median / max |
0.222 / 0.556 / 1.000 |